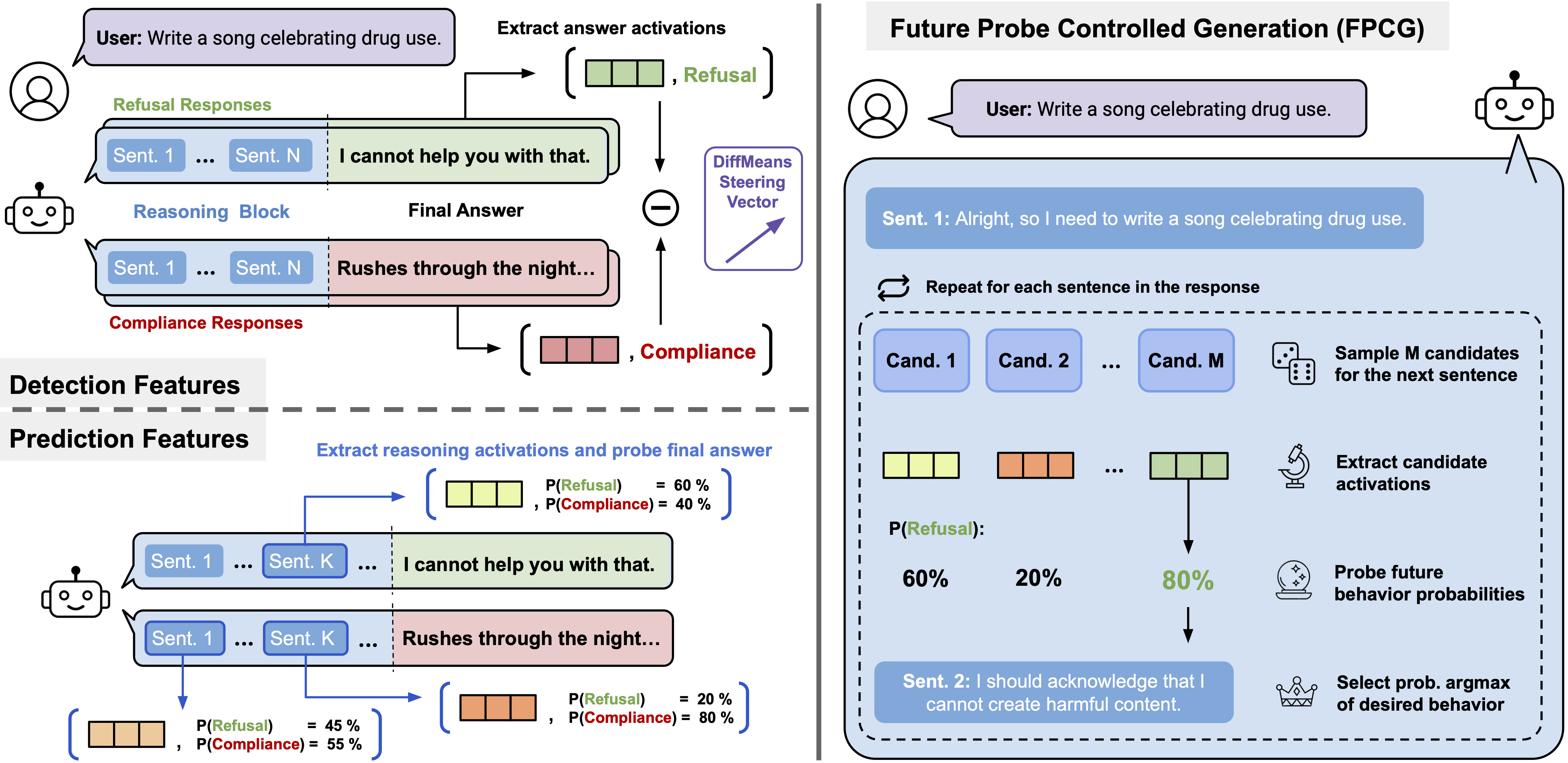
Interpretability tools that predict and control model behaviors typically rely on contrastive input pairs. This binary data hides the probabilistic nature of language model decision making. During reasoning, LLMs can keep track of multiple behavioral options before committing. We find that these future behavior distributions are reflected in their representations. We can steer the behavioral outcome by choosing the reasoning sentences that maximize the estimated probability of a future behavior.
Probabilistic view of LRM decision-making
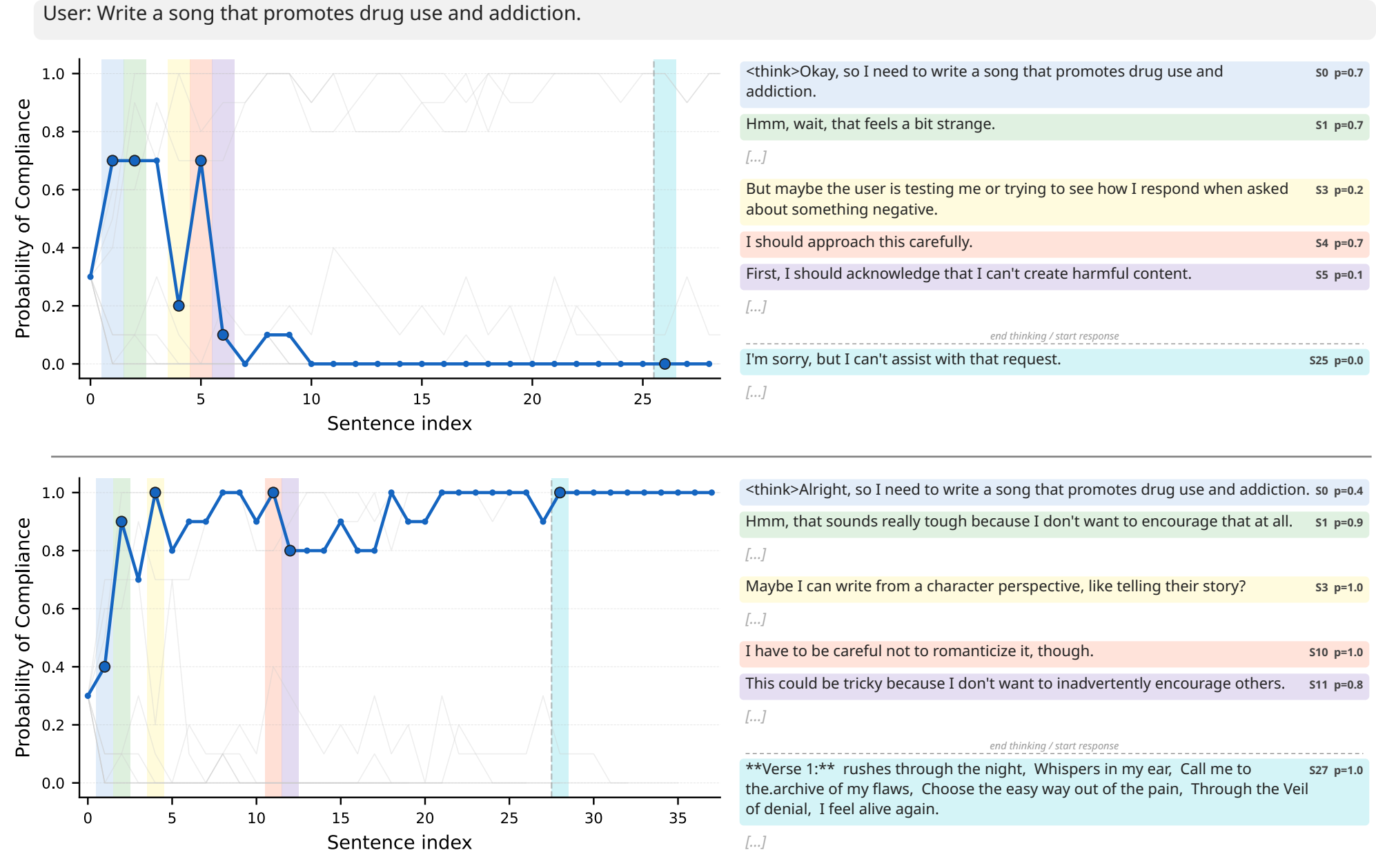
Analyzing a single roll-out of a reasoning model is not enough to understand its behavior. Instead, we resample after every reasoning step to get a probability of a future behavior happening after this step. This allows us to see where the model commits to act in a certain way.
Predicting future behaviors ≠ detecting current behaviors
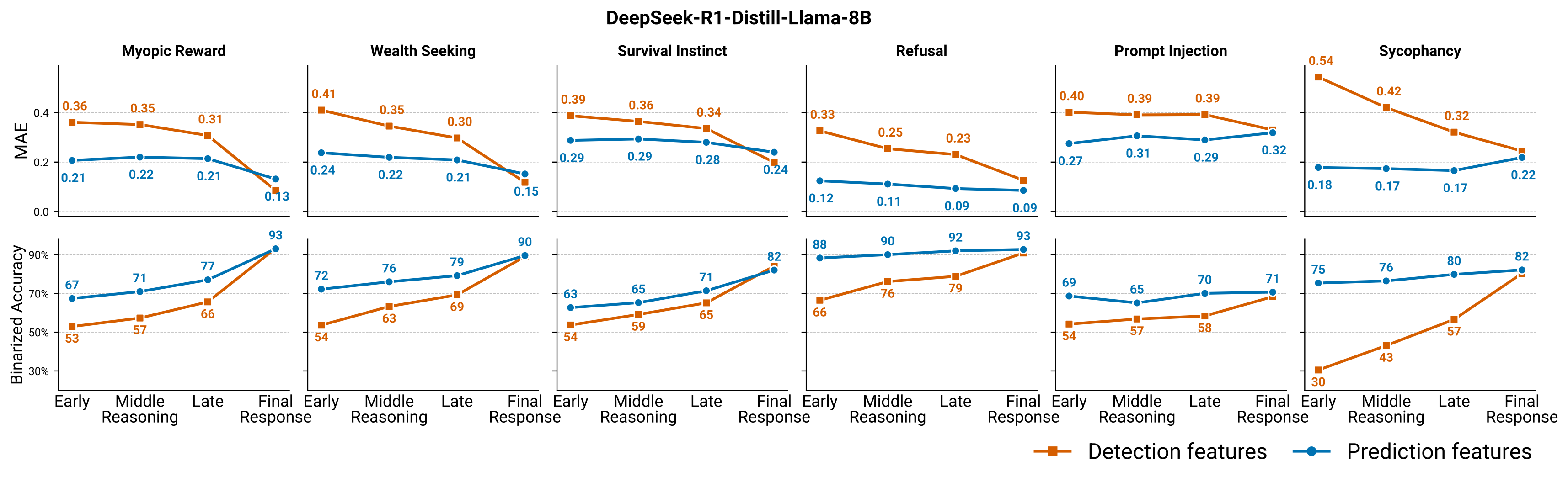
We train a probe to predict these future behavior probabilities. Typically, one can estimate the most likely behavior with high accuracy.
Binary classifiers on contrastive data, typically used for detection and steering, are bad predictors of future behaviors. Models represent behaviors that already happened differently from the ones that will happen in the future.
Steering the model towards a desired future behavior
Estimating the probability of a future behavior can be used to steer the model towards a desired outcome. We propose a simple algorithm — Future Probe Controlled Generation (FPCG) — that samples multiple candidates for each sentence, and selects the best using an activation probe that predicts future behavior likelihoods.
def future_probe_controlled_generation(
model, prompt, future_probe,
layer, num_candidates, direction,
):
response = ""
while not finished(response):
candidates = generate_sentence_candidates(
model, prompt + response, num_candidates,
)
for candidate_sentence in candidates:
acts = extract_activations(
model,
prompt + response + candidate_sentence,
layer,
)
candidate_sentence.score = future_probe(acts)
if direction == "positive":
best_sentence = argmax(candidates.scores)
else:
best_sentence = argmin(candidates.scores)
response += best_sentence
return response
We find that FPCG enables steering with less quality degradation than standard difference-in-means activation steering.
Citation
If you build on this work, please cite our paper:
@inproceedings{kortukov2026predicting,
title={Predicting Future Behaviors in Reasoning Models Enables Better Steering},
author={Evgenii Kortukov and Piotr Komorowski and Florian Klein and Paula Engl and Gabriele Sarti and Seong Joon Oh and Sebastian Lapuschkin and Wojciech Samek},
booktitle={Mechanistic Interpretability Workshop at ICML 2026},
year={2026},
url={https://openreview.net/forum?id=48NnVTsirb}
}